
TL;DR Trillion-scale corpora can be searched in <0.3s with soft matching that preserves word order and semantic similarity.
Masataka Yoneda1,2 Yusuke Matsushita3 Go Kamoda4,5 Kohei Suenaga3,2 Takuya Akiba6,7 Masaki Waga3,2 Sho Yokoi5,7,8
1The University of Tokyo 2NII 3Kyoto University 4SOKENDAI 5NINJAL 6Sakana AI 7Tohoku University 8RIKEN
TL;DR Trillion-scale corpora can be searched in <0.3s with soft matching that preserves word order and semantic similarity.
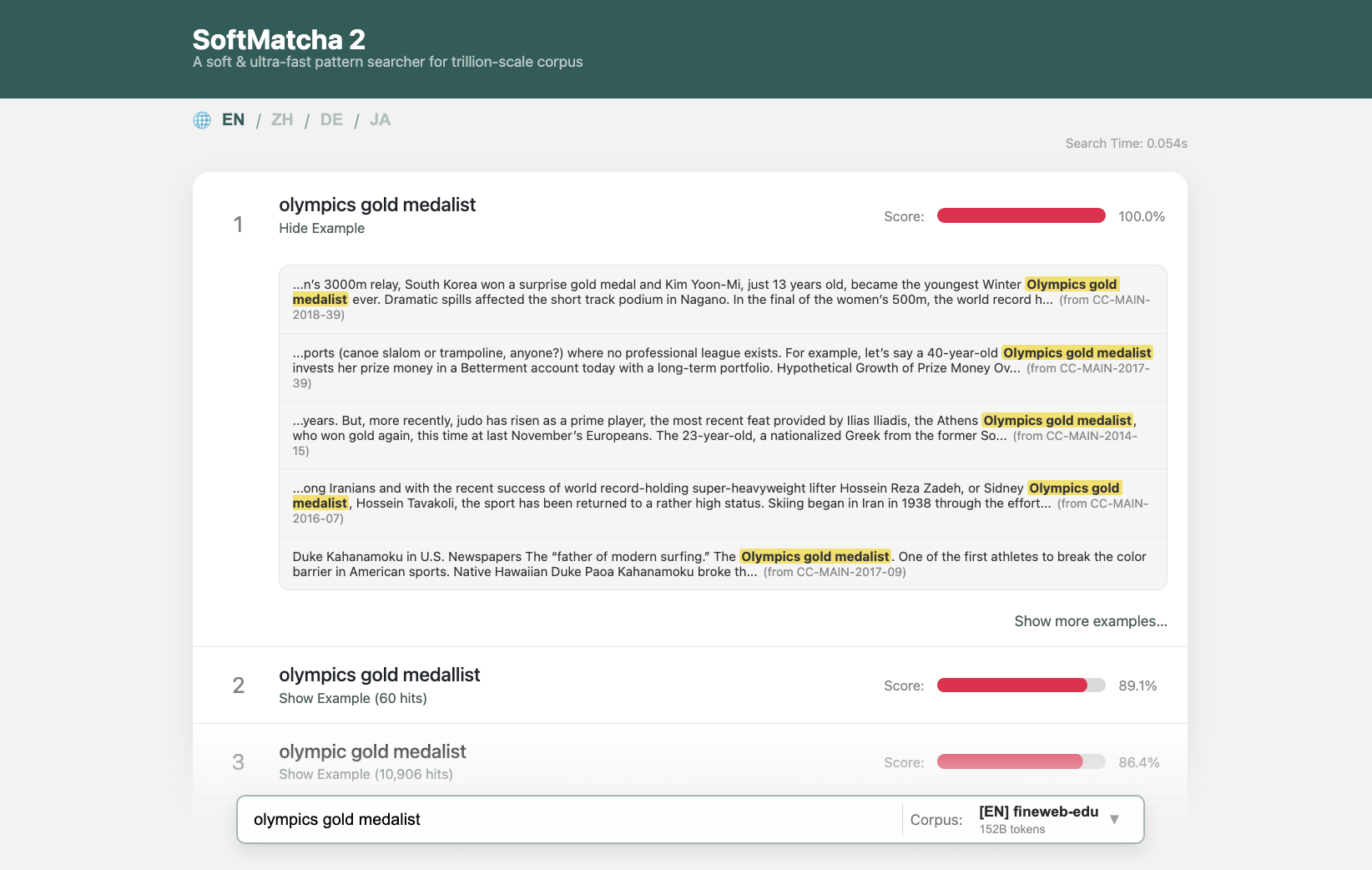
We present an ultra-fast and flexible search algorithm that enables search over trillion-scale natural language corpora in under 0.3 seconds while handling semantic variations (substitution, insertion, and deletion). Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning. We theoretically show that the proposed method suppresses exponential growth in the search space with respect to query length by leveraging statistical properties of natural language. In experiments on FineWeb-Edu (1.4T tokens), we show that our method achieves significantly lower search latency than existing methods: infini-gram, infini-gram mini, and SoftMatcha. As a practical application, we demonstrate that our method identifies benchmark contamination in training corpora, unidentified by existing approaches. We also provide an online demo of fast, soft search across corpora in seven languages.
@article{yoneda-preprint-2026-softmatcha2,
title = "{SoftMatcha 2: A Fast and Soft Pattern Matcher for
Trillion-scale Corpora}",
author = "Yoneda, Masataka and Matsushita, Yusuke and Kamoda, Go and
Suenaga, Kohei and Akiba, Takuya and Waga, Masaki and Yokoi,
Sho",
journal = "arXiv [cs.CL]",
month = "11~" # feb,
year = 2026,
url = "http://dx.doi.org/10.48550/arXiv.2602.10908",
archivePrefix = "arXiv",
primaryClass = "cs.CL",
doi = "10.48550/arXiv.2602.10908"
}